
用年度数据绘制大熊猫数据框

我有一个格式的数据框
value
2000-01-01 1
2000-03-01 2
2000-06-01 15
2000-09-01 3
2000-12-01 7
2001-01-01 1
2001-03-01 3
2001-06-01 8
2001-09-01 5
2001-12-01 3
2002-01-01 1
2002-03-01 1
2002-06-01 8
2002-09-01 5
2002-12-01 19
(索引是日期时间),我需要逐年绘制所有结果以比较每3个月的结果(数据也可以是每月),再加上所有年份的平均值。
我可以轻松地分别绘制它们,但是由于有索引,它会根据索引移动图:
fig, axes = plt.subplots()
df['2000'].plot(ax=axes, label='2000')
df['2001'].plot(ax=axes, label='2001')
df['2002'].plot(ax=axes, label='2002')
axes.plot(df["2000":'2002'].groupby(df["2000":'2002'].index.month).mean())
因此,这不是理想的结果。我似乎在这里有一些答案,但是您必须合并,创建多索引并进行绘图。如果其中一个数据帧具有NaN或缺少值,则可能非常麻烦。有熊猫可以做到吗?
问题答案:
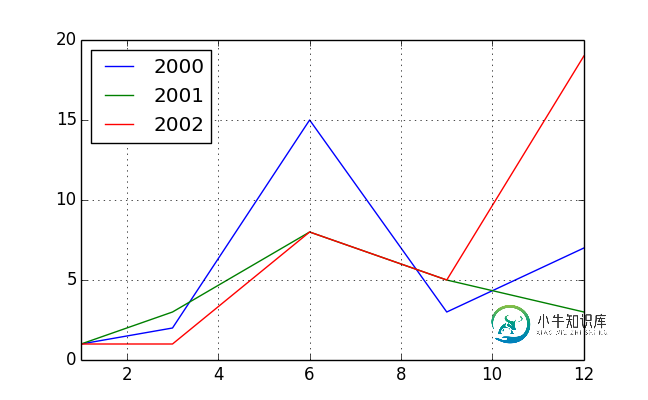
这是你想要的吗?您可以在转换后添加均值。
df = pd.DataFrame({'value': [1, 2, 15, 3, 7, 1, 3, 8, 5, 3, 1, 1, 8, 5, 19]},
index=pd.DatetimeIndex(['2000-01-01', '2000-03-01', '2000-06-01', '2000-09-01',
'2000-12-01', '2001-01-01', '2001-03-01', '2001-06-01',
'2001-09-01', '2001-12-01', '2002-01-01', '2002-03-01',
'2002-06-01', '2002-09-01', '2002-12-01']))
pv = pd.pivot_table(df, index=df.index.month, columns=df.index.year,
values='value', aggfunc='sum')
pv
# 2000 2001 2002
# 1 1 1 1
# 3 2 3 1
# 6 15 8 8
# 9 3 5 5
# 12 7 3 19
pv.plot()
-
我有这种熊猫。数据框。“a”、“b”是获得“x”和“y”时的条件。 我需要绘制关于相同条件的(x,y)结肠的折线图。预期结果图为: 当然,这个图像是由以下代码手动给出的: 我的问题是,当获得一个包含条件列x和y的数据帧时,如何动态地绘制如上所述的图。 列名是固定的。但是,条件列的值是动态更改的。因此,我不能使用10、20、100、200的值。 如果我有下面的“用a和b过滤”方法,我认为问题解决了:
-
我有这个熊猫数据框 这就给了我: 我该怎么办 做一个新的人物, 将标题添加到图"标题这里" 以某种方式创建一个映射,这样标签不是29,30等,而是“29周”,“30周”等。 将图表的较大版本保存到我的计算机(例如10 x 10英寸) 这件事我已经琢磨了一个小时了!
-
问题内容: 我的数据是: 是使用转换的字符串。 这样的情节非常前卫(这些不是我的实际情节): 我如何像这样平滑它: 我知道本文中提到的内容(这是我从中获取图像的地方),但是如何将其应用于熊猫时间序列? 我发现了一个名为Vincent的很棒的库,它可以处理Pandas,但它不支持Python 2.6。 问题答案: 得到它了。在这个问题的帮助下,我做了以下工作: 从几分钟到几秒重新采样。 \ >>>
-
问题内容: 我注意到程序中存在一个错误,发生该错误的原因是因为熊猫似乎是通过引用熊猫数据框而不是通过值进行复制。我知道不可变对象将始终通过引用传递,但pandas数据帧不是不可变的,因此我不明白为什么它通过引用传递。谁能提供一些信息? 谢谢!安德鲁 问题答案: Python中的所有函数都是“按引用传递”,没有“按值传递”。如果要显式复制pandas对象,请尝试。
-
在学习熊猫的过程中,我已经尝试了好几个月来找出这个问题的答案。我在日常工作中使用SAS,这是非常好的,因为它提供了非核心支持。然而,SAS作为一个软件是可怕的,原因还有很多。 有一天,我希望用python和pandas取代SAS的使用,但我目前缺乏大型数据集的核心外工作流。我说的不是需要分布式网络的“大数据”,而是文件太大而无法放入内存,但又太小而无法装入硬盘。 我的第一个想法是使用将大型数据集保
-
问题内容: 我有月度数据。我想将其转换为1月份从1月份开始的3个月的“期间”。因此,在下面的示例中,前三个月的汇总将转换为q2的开始(所需格式:1996q2)。而将三个月度值汇总在一起而得出的数据值是三列的平均值。从概念上讲,并不复杂。有谁知道如何一口气做到这一点?潜在地,我可以通过循环来做很多艰苦的工作,并从中进行硬编码,但是我是熊猫的新手,正在寻找比暴力更聪明的东西。 所以我在寻找: 问题答案
-
问题内容: 我有一个熊猫系列,目前看起来像这样: 我想从根本上将其重塑成一个看起来像这样的数据框… 即。逻辑构造,指出每个观察(行)属于哪个类别。 我能够编写基于循环的代码来解决该问题,但是鉴于我需要处理的行数众多,这将非常缓慢。 有谁知道针对这种问题的矢量化解决方案?我将不胜感激。 编辑:有509个类别,我确实有一个清单。 问题答案:
-
问题内容: 我有一个数据框 ,它有一 列。我想创建两个新的数据框。一个包含 年份等于的所有行 ,另一个数据框包含 年份不等于的所有行 。我知道您可以这样做,`df.ix[‘2000-1-1’ ‘2001-1-1’]`但是为了获得2000年中没有的所有行,需要创建2个额外的数据帧,然后进行串联/联接。 有这样的办法吗? 这段代码不起作用,但是有什么类似的方法吗? 问题答案: 您可以使用datetim