
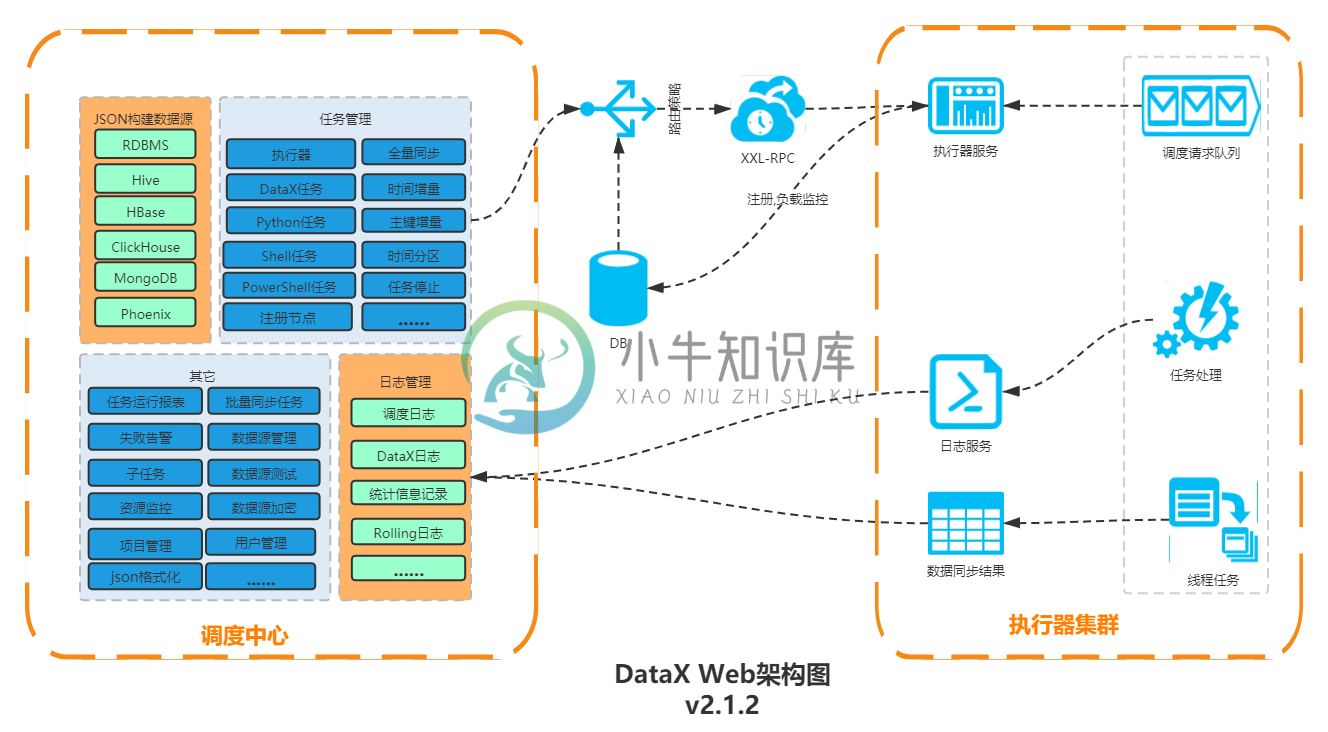
DataX Web是在DataX之上开发的分布式数据同步工具,提供简单易用的操作界面,降低用户使用DataX的学习成本,缩短任务配置时间,避免配置过程中出错。用户可通过页面选择数据源即可创建数据同步任务,RDBMS数据源可批量创建数据同步任务,支持实时查看数据同步进度及日志并提供终止同步功能,集成并二次开发xxl-job可根据时间、自增主键增量同步数据。
任务"执行器"支持集群部署,支持执行器多节点路由策略选择,支持超时控制、失败重试、失败告警、任务依赖,执行器CPU.内存.负载的监控等等。后续还将提供更多的数据源支持、数据转换UDF、表结构同步、数据同步血缘等更为复杂的业务场景。

Architecture diagram:
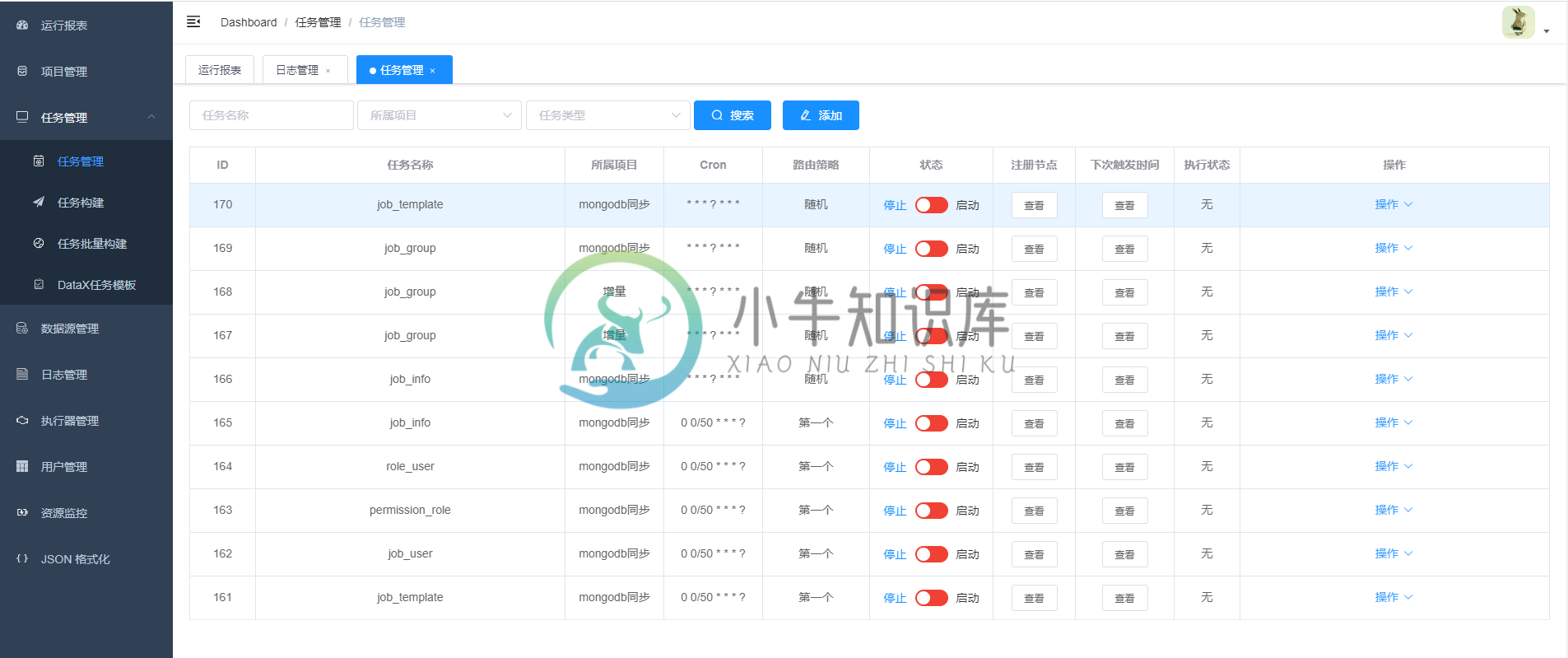
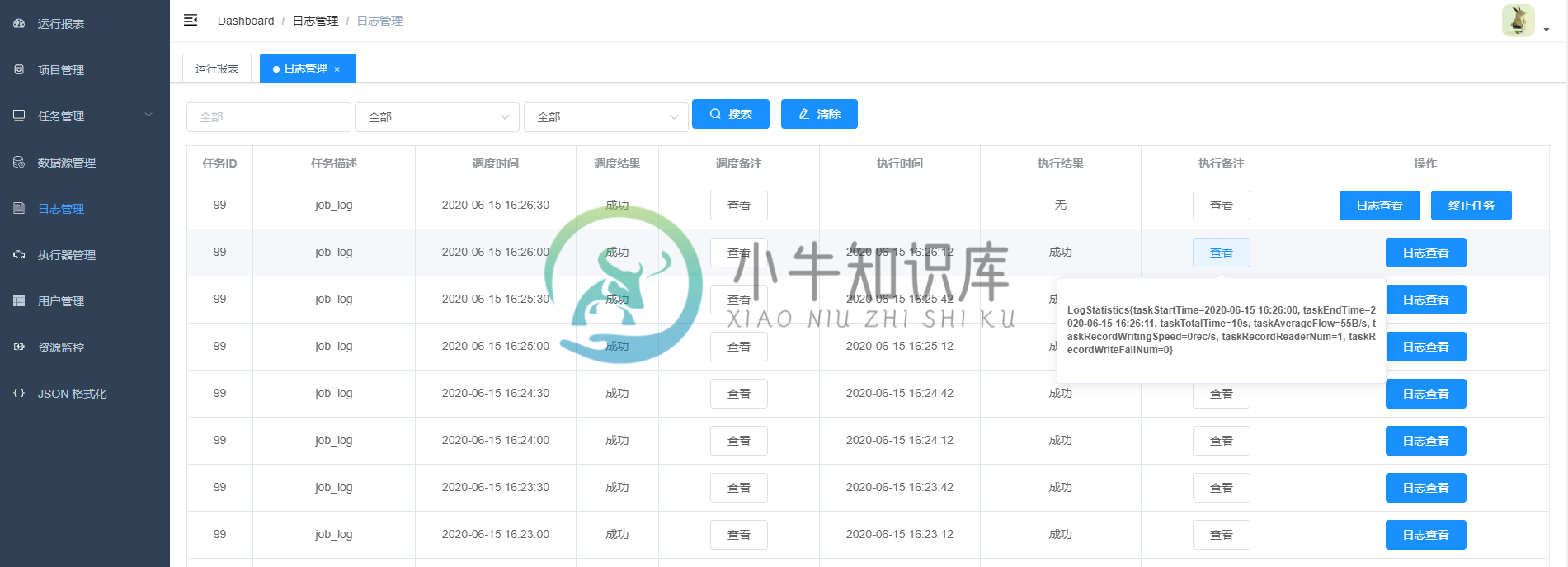
项目部分截图





-
1.安装mysql5.7 a.创建目录下载安装rpm包 mkdir -p /opt/software & cd /opt/software/ & wget -i -c http://dev.mysql.com/get/mysql57-community-release-el7-10.noarch.rpm & du -sh mysql57-community-release-el7-10.noar
-
Lock Redisson 分布式可重入锁,实现了 java.util.concurrent.locks.Lock 接口并支持 TTL。 RLock lock = redisson.getLock("anyLock"); // Most familiar locking method lock.lock(); // Lock time-to-live support // releases loc
-
分布式支持 数据访问层支持分布式数据库,包括读写分离,要启用分布式数据库,需要开启数据库配置文件中的deploy参数: return [ // 启用分布式数据库 'deploy' => 1, // 数据库类型 'type' => 'mysql', // 服务器地址 'hostname' => '192.168.1.1,19
-
一个成功的技术,现实的优先级必须高于公关,你可以糊弄别人,但糊弄不了自然规律。 ——罗杰斯委员会报告(1986) 在本书的第一部分中,我们讨论了数据系统的各个方面,但仅限于数据存储在单台机器上的情况。现在我们到了第二部分,进入更高的层次,并提出一个问题:如果多台机器参与数据的存储和检索,会发生什么? 你可能会出于各种各样的原因,希望将数据库分布到多台机器上: 可扩展性 如果你的数据量、读取负载、写
-
你现在拥有了一个远程 Git 版本库,能为所有开发者共享代码提供服务,在一个本地工作流程下,你也已经熟悉了基本 Git 命令。你现在可以学习如何利用 Git 提供的一些分布式工作流程了。 这一章中,你将会学习如何作为贡献者或整合者,在一个分布式协作的环境中使用 Git。 你会学习为一个项目成功地贡献代码,并接触一些最佳实践方式,让你和项目的维护者能轻松地完成这个过程。另外,你也会学到如何管理有很多
-
我们可以通过下面的简单算法实现该目的: 检查本地缓存的键(key); 如果本地缓存存在该键,则返回它的值; 如果本地缓存不存在该键,则尝试在分布式缓存中找; 如果分布式缓存存在该键,则返回它的值并把它添加到本地缓存; 如果分布式缓存不存在该键,则从数据库中获取,并添加到本地和分布式缓存,最后返回该值。 当在本地缓存服务器中缓存一些信息时,使用这种方式,它还将信息缓存到分布式缓存,但这一次,如果其他
-
同传统的集中式版本控制系统(CVCS)不同,Git 的分布式特性使得开发者间的协作变得更加灵活多样。 在集中式系统中,每个开发者就像是连接在集线器上的节点,彼此的工作方式大体相像。 而在 Git 中,每个开发者同时扮演着节点和集线器的角色——也就是说,每个开发者既可以将自己的代码贡献到其他的仓库中,同时也能维护自己的公开仓库,让其他人可以在其基础上工作并贡献代码。 由此,Git 的分布式协作可以为
-
这里我的疑问是,如果我使用多个分布式数据库,cam如何在配置(application.properties)中提到不同的DB源URL?目前我正在使用以下结构来使用一个数据库, 就像上面那样。 所以,如果我使用多个DB用于多个区域,我如何在这里给出有条件的配置?我是微服务世界和分布式数据库设计模式的新手。
-
我将hazelcast服务器分布在多个节点上。我假设hazelcast将在集群中分发任何IMap数据,这样每个节点都将拥有属于映射的数据。这是建立集群后默认情况下应该发生的事情,还是需要在hazelcast.xml中设置代码或配置?