
Python数据可视化:箱线图多种库画法

概念
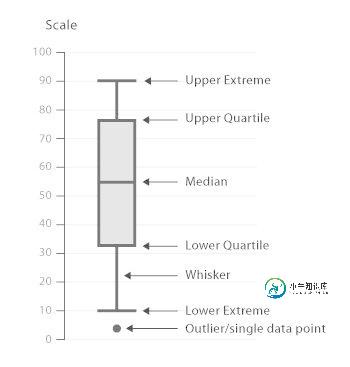
箱线图通过数据的四分位数来展示数据的分布情况。例如:数据的中心位置,数据间的离散程度,是否有异常值等。
把数据从小到大进行排列并等分成四份,第一分位数(Q1),第二分位数(Q2)和第三分位数(Q3)分别为数据的第25%,50%和75%的数字。

四分位间距(Interquartilerange(IQR))=上分位数(upper quartile)-下分位数(lower quartile)
箱线图分为两部分,分别是箱(box)和须(whisker)。箱(box)用来表示从第一分位到第三分位的数据,须(whisker)用来表示数据的范围。
箱线图从上到下各横线分别表示:数据上限(通常是Q3+1.5IQR),第三分位数(Q3),第二分位数(中位数),第一分位数(Q1),数据下限(通常是Q1-1.5IQR)。有时还有一些圆点,位于数据上下限之外,表示异常值(outliers)。
(注:如果数据上下限特别大,那么whisker将显示数据的最大值和最小值。)
案例
1. 使用pandas自带的函数
使用pandas里的dataframe数据结构存放待显示的数据。如果希望显示的各个数据列表中,数据长度不一致,可以先用Series函数转换为Series数据,再存储到dataframe中,对应index的value值若不存在则为NaN。
下面我们随机生成4组数据,看看他们的箱线图。
【代码】
import numpy as np
import pandas as pd
from matplotlib import pyplot as plt
def list_generator(mean, dis, number): # 封装一下这个函数,用来后面生成数据
return np.random.normal(mean, dis * dis, number) # normal分布,输入的参数是均值、标准差以及生成的数量
# 我们生成四组数据用来做实验,数据量分别为70-100
y1 = list_generator(0.8531, 0.0956, 70)
y2 = list_generator(0.8631, 0.0656, 80)
y3 = list_generator(0.8731, 0.1056, 90)
y4 = list_generator(0.8831, 0.0756, 100)
# 如果数据大小不一,记得需要下面语句,把数组变为series
y1 = pd.Series(np.array(y1))
y2 = pd.Series(np.array(y2))
y3 = pd.Series(np.array(y3))
y4 = pd.Series(np.array(y4))
data = pd.DataFrame({"1": y1, "2": y2, "3": y3, "4": y4, })
data.boxplot() # 这里,pandas自己有处理的过程,很方便哦。
plt.ylabel("ylabel")
plt.xlabel("xlabel") # 我们设置横纵坐标的标题。
plt.show()
【效果】
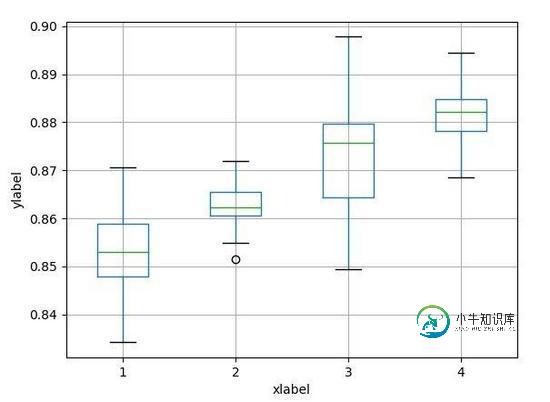
上面的箱线图很简单,给出数据后,几行代码就能生成,不过这是简单的箱线图。下面再看看稍微复杂点的。
2. 使用matplotlib库画箱线图
我们上面介绍了使用pandas画箱线图,几句命令就可以了。但是稍微复杂点的可以使用matplotlib库。matplotlib代码稍微复杂点,但是很灵活。细心点同学会发现pandas里面的画图也是基于此库的,下面给你看看pandas里面的源码:
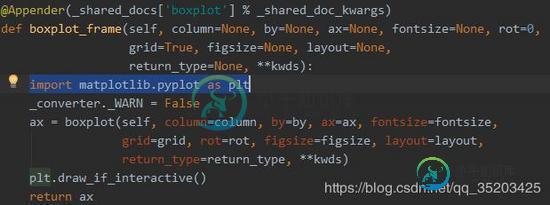
通过源码可以看到pandas内部也是通过调用matplotlib来画图的。那下面我们自己实现用matplotlib画箱线图。
我们简单模拟一下,男女生从20岁,30岁的花费对比图,使用箱线图来可视化一下。
【代码】
import numpy as np import matplotlib.pyplot as plt fig, ax = plt.subplots() # 子图 def list_generator(mean, dis, number): # 封装一下这个函数,用来后面生成数据 return np.random.normal(mean, dis * dis, number) # normal分布,输入的参数是均值、标准差以及生成的数量 # 我们生成四组数据用来做实验,数据量分别为70-100 # 分别代表男生、女生在20岁和30岁的花费分布 girl20 = list_generator(1000, 29.2, 70) boy20 = list_generator(800, 11.5, 80) girl30 = list_generator(3000, 25.1056, 90) boy30 = list_generator(1000, 19.0756, 100) data=[girl20,boy20,girl30,boy30,] ax.boxplot(data) ax.set_xticklabels(["girl20", "boy20", "girl30", "boy30",]) # 设置x轴刻度标签 plt.show()
【效果】
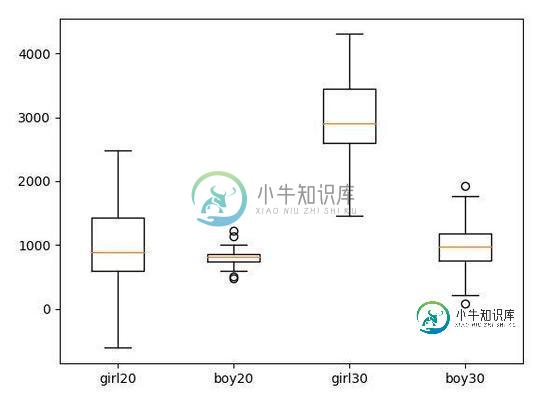
从上面随机模拟,看出来男生花费赶不上女生吧,尤其是30岁以后,女生摔男生一大截啊。(模拟数据,请勿当真)
仔细看上面的图,感觉还是不太好,既然男女生对比,那是不是要分组,男女生放一块,然后再根据年龄段比较,这样比较才直观。
那我们就稍微改动上面一点点代码,实现男女生箱线图挨得近一点。
【代码】
import numpy as np import matplotlib.pyplot as plt fig, ax = plt.subplots() # 子图 def list_generator(mean, dis, number): # 封装一下这个函数,用来后面生成数据 return np.random.normal(mean, dis * dis, number) # normal分布,输入的参数是均值、标准差以及生成的数量 # 我们生成四组数据用来做实验,数据量分别为70-100 # 分别代表男生、女生在20岁和30岁的花费分布 girl20 = list_generator(1000, 29.2, 70) boy20 = list_generator(800, 11.5, 80) girl30 = list_generator(3000, 25.1056, 90) boy30 = list_generator(1000, 19.0756, 100) data=[girl20,boy20,girl30,boy30,] # 用positions参数设置各箱线图的位置 ax.boxplot(data,positions=[0, 0.6, 3, 3.7,])# 就是后面加了位置 ax.set_xticklabels(["girl20", "boy20", "girl30", "boy30",]) # 设置x轴刻度标签 plt.show()
【效果】

这样看一下,是不是男女生根据年龄段分组了呢,稍微比上面好看些,也直观一些。这样既能看出年龄段的对比,又能看出男女生的对比。
同样,如果想要箱线图旋转90°,那么也是在在 boxplot命令里加上参数 vert=False即可。如果想要更多设置,可以基于 boxplot函数参数进行修改,其函数定义如下:
boxplot(self, x, notch=None, sym=None, vert=None, whis=None, positions=None, widths=None, patch_artist=None, bootstrap=None, usermedians=None, conf_intervals=None, meanline=None, showmeans=None, showcaps=None, showbox=None, showfliers=None, boxprops=None, labels=None, flierprops=None, medianprops=None, meanprops=None, capprops=None, whiskerprops=None, manage_xticks=True, autorange=False, zorder=None)
3. 使用seaborn库和matplotlib来画箱线图
Seaborn是基于matplotlib的Python可视化库。 它提供了一个高级界面来绘制有吸引力的统计图形。Seaborn其实是在matplotlib的基础上进行了更高级的API封装,从而使得作图更加容易,不需要经过大量的调整就能使你的图变得精致。但应强调的是,应该把Seaborn视为matplotlib的补充,而不是替代物。
函数定义:
boxplot(x=None, y=None, hue=None, data=None, order=None, hue_order=None, orient=None, color=None, palette=None, saturation=.75, width=.8, dodge=True, fliersize=5, linewidth=None, whis=1.5, notch=False, ax=None, **kwargs)
【参数讲解】 x,y:dataframe中的列名(str)或者矢量数据
- data:dataframe或者数组
- palette:调色板,控制图像的色调
- hue(str):dataframe的列名,按照列名中的值分类形成分类的条形图
- order, hue_order (lists of strings):用于控制条形图的顺序
- orient:"v"|"h" 用于控制图像使水平还是竖直显示(这通常是从输入变量的dtype推断出来的,此参数一般当不传入x、y,只传入data的时候使用)
- fliersize:float,用于指示离群值观察的标记大小
- whis:确定离群值的上下界(IQR超过低和高四分位数的比例),此范围之外的点将被识别为异常值。IQR指的是上下四分位的差值。
- width:float,控制箱型图的宽度
我们还是基于上面男女花费案例来说,不过这里我们把数据进行了整理,做成了数据框dataframe。
【包含的库】
import pandas as pd
import numpy as np
import seaborn as sns
import matplotlib.pyplot as plt
# plt.rc("font", family="SimHei", size="15") 避免中文乱码,可不用
【代码第一部分】数据生成
def list_generator(mean, dis, number): # 封装一下这个函数,用来后面生成数据 return np.random.normal(mean, dis * dis, number) # normal分布,输入的参数是均值、标准差以及生成的数量 # 我们生成四组数据用来做实验,数据量分别为70-100 # 分别代表男生、女生在20岁和30岁的花费分布 # 构造数据库DataFrame num = 100 # 每组100个样本 girl20 = list_generator(1000, 29.2, num) boy20 = list_generator(800, 11.5, num) girl30 = list_generator(3000, 25.1056, num) boy30 = list_generator(1000, 19.0756, num) girl_sex = ['female' for _ in range(num)] boy_sex = ['male' for _ in range(num)] age20 = [20 for _ in range(num)] age30 = [30 for _ in range(num)] girl_d1 = pd.DataFrame({'cost': girl20, 'sex': girl_sex, 'age': age20}) boy_d1 = pd.DataFrame({'cost': boy20, 'sex': boy_sex, 'age': age20}) girl_d2 = pd.DataFrame({'cost': girl30, 'sex': girl_sex, 'age': age30}) boy_d2 = pd.DataFrame({'cost': boy30, 'sex': boy_sex, 'age': age30}) data = pd.concat([girl_d1, boy_d1, girl_d2, boy_d2]) print(data.head())
数据长啥样?下面是给出的数据框前面的部分,一共400个样本,分性别和年龄。
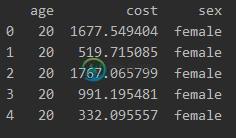
【代码第二部分】使用seaborn库画图
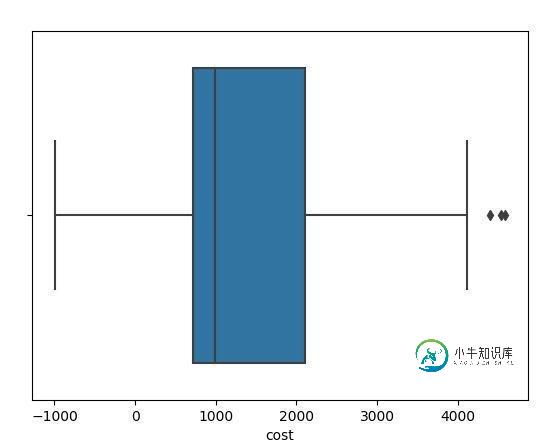
简单看看所有数据的分布情况:
sns.boxplot(x="age", y="cost", data=data, hue="sex", width=0.5, linewidth=1.0, palette="Set3")
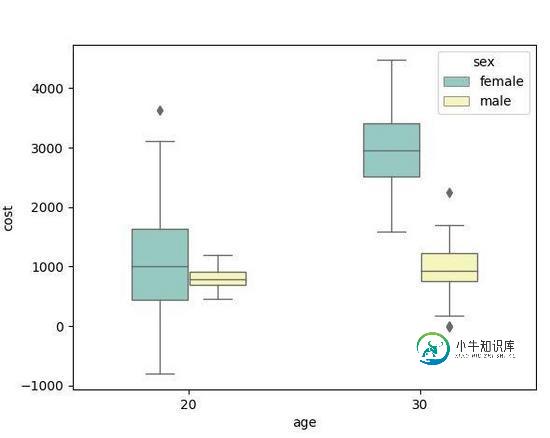
根据性别分组:
sns.boxplot(x="age", y="cost", data=data, hue="sex", width=0.5, linewidth=1.0, palette="Set3")
根据年龄分组:
sns.boxplot(x="sex", y="cost", data=data, hue="age", width=0.5, linewidth=1.0, palette="Set3")
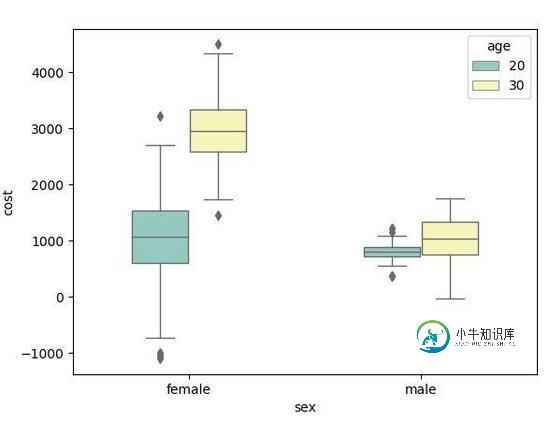
上面这些是seaborn库的简单使用,可以通过年龄看男女花费比较,也可以根据性别看不同年龄段的花费比较,还是比较直观的。当然除此之外还有很多其他的炫技,大家可以自己尝试。
总结
从上面来看,虽然我们是采用不同方法来画箱线图,但是最基本的都是调用matplotlib库,这里面pandas是最简单的箱线图可视化,但是不灵活。而matplotlib虽然灵活,但是需要慢慢调,而且复杂。相比之下seaborn更加酷炫,而且图还更好看。上面例子都是本人亲测,一个个对比,原创文章,大家如果有其他问题可以留言讨论。
-
本文向大家介绍Python数据可视化之画图,包括了Python数据可视化之画图的使用技巧和注意事项,需要的朋友参考一下 安装数据可视化模块matplotlib:pip install matplotlib 导入matplotlib模块下的pyplot 1 折线图 2 散点图 用两种方法 第一种:只需将函数polt换成scatter即可. 第二种方法:在polt函数里添加第三个参数 “o”. 可以更
-
本文向大家介绍python使用pyecharts库画地图数据可视化的实现,包括了python使用pyecharts库画地图数据可视化的实现的使用技巧和注意事项,需要的朋友参考一下 python使用pyecharts库画地图数据可视化导库中国地图代码结果世界地图代码结果省级地图代码结果地级市地图代码结果 导库 中国地图 代码 结果 世界地图代码 结果 省级地图代码 结果 地级市地图代码 结果 到此这
-
问题内容: 我很少(每月/每季度)使用Microsoft SQL Server 2005数据库视图生成数百个Crystal Reports报表。这些视图是否一直在浪费我的时间,而不是在浪费它们的CPU周期和RAM?由于我很少从视图中读取内容,我应该改用存储过程,临时表还是短暂的普通表吗? 我不是DBA,所以我不知道数据库服务器内部幕后发生的事情。 是否有太多的数据库视图?什么是最佳做法? 问题答案
-
本文向大家介绍Python数据可视化库seaborn的使用总结,包括了Python数据可视化库seaborn的使用总结的使用技巧和注意事项,需要的朋友参考一下 seaborn是python中的一个非常强大的数据可视化库,它集成了matplotlib,下图为seaborn的官网,如果遇到疑惑的地方可以到官网查看。http://seaborn.pydata.org/ 从官网的主页我们就可以看出,sea
-
本文向大家介绍Python数据可视化常用4大绘图库原理详解,包括了Python数据可视化常用4大绘图库原理详解的使用技巧和注意事项,需要的朋友参考一下 今天我们就用一篇文章,带大家梳理matplotlib、seaborn、plotly、pyecharts的绘图原理,让大家学起来不再那么费劲! 1. matplotlib绘图原理 关于matplotlib更详细的绘图说明,大家可以参考下面这篇文章,相