
python抓取需要扫微信登陆页面

一,抓取情况描述
1.抓取的页面需要登陆,以公司网页为例,登陆网址https://app-ticketsys.hezongyun.com/index.php ,(该网页登陆方式微信扫码登陆)
2.需要抓取的内容如下图所示:
需要提取
工单对应编号,如TK-2960
工单发起时间,如2018-08-17 11:12:13
工单标题内容,如设备故障
工单正文内容,如最红框所示

二,网页分析
1.按按Ctrl + Shift + I或者鼠标右键点击检查进入开发人员工具。
可以看到页面显示如下:

主要关注点如上图框住和划线处
首先点击网络,记住以下信息将用于代码修改处。
Resquest URL:https: //app-ticketsys.hezongyun.com/index.php/ticket/ticket_list/init这个是需要爬取页面的信息请求Menthod:GET饼干:用于需要登陆页面User-Agent:Mozilla / 5.0(Windows NT 10.0; Win64; x64)AppleWebKit / 537.36(KHTML,类似Gecko)Chrome / 67.0.3396.62 Safari / 537.36
记住以上信息后粗略了解网页树形结构用BeatifulSoup中SELEC怎么取出内容
示例:的H1M1一段代码如下:
html =“”“ <html> <head> <title>睡鼠的故事</ title> </ head> <body> <p class =”title“name =”dromouse“> <b>睡鼠的故事</ b > </ p> <p class =“story”>从前有三个小姐妹;他们的名字是 <a href =“http://example.com/elsie”class =“sister”id =“ link1“> <! - Elsie - > </a>, <a href="http://example.com/lacie" rel="external nofollow" class="sister" id="link2"> Lacie </a>和 <a href =“http://example.com/tillie”class =“sister”id =“link3”> Tillie </a>; 他们住在井底。</ p> <p class =“story”> ... </ p> “”“
如果我们喝汤得到了上面那段HTML的结构提取内容方法如下
1.通过标签名查找soup.select( '标题'),如需要取出含有一个标签的内容则soup.select( 'a')的
2.通过类名查找soup.select( 'CLASS_NAME ')如取出标题的内容则soup.select('。标题')
3.通过ID名字查找soup.select( '#ID_NAME')如取出ID = LINK2的内容则soup.select( '#LINK2')
上述元素名字可以利用左上角箭头取出,如下图

三,程序编写
# -*- coding:utf-8 -*-
import requests
import sys
import io
from bs4 import BeautifulSoup
import sys
import xlwt
import urllib,urllib2
import re
def get_text():
#登录后才能访问的网页,这个就是我们在network里查看到的Request URL
url = 'https://app-ticketsys.hezongyun.com/index.php/ticket/ticket_iframe/'
#浏览器登录后得到的cookie,这个就是我们在network里查看到的Coockie
cookie_str = r'ci_ticketsys_session=‘***********************************'
#把cookie字符串处理成字典
cookies = {}
for line in cookie_str.split(';'):
key, value = line.split('=', 1)
cookies[key] = value
#设置请求头
headers = {'User-Agent':'Mozilla/5.0(Windows NT 10.0; Win64;x64)AppleWebKit/537.36 (KHTML, like Gecko)Chrome/67.0.3396.62 Safari/537.36'}
#在发送get请求时带上请求头和cookies
resp = requests.get(url, cookies = cookies,headers = headers)
soup = BeautifulSoup(resp.text,"html.parser")
print soup
上述代码就能得到登陆网页的HTML源码,这个源码呈一个树形结构,接下来针对需求我们提取需要的内容进行提取
我们需要工单号,对应时间,对应标题
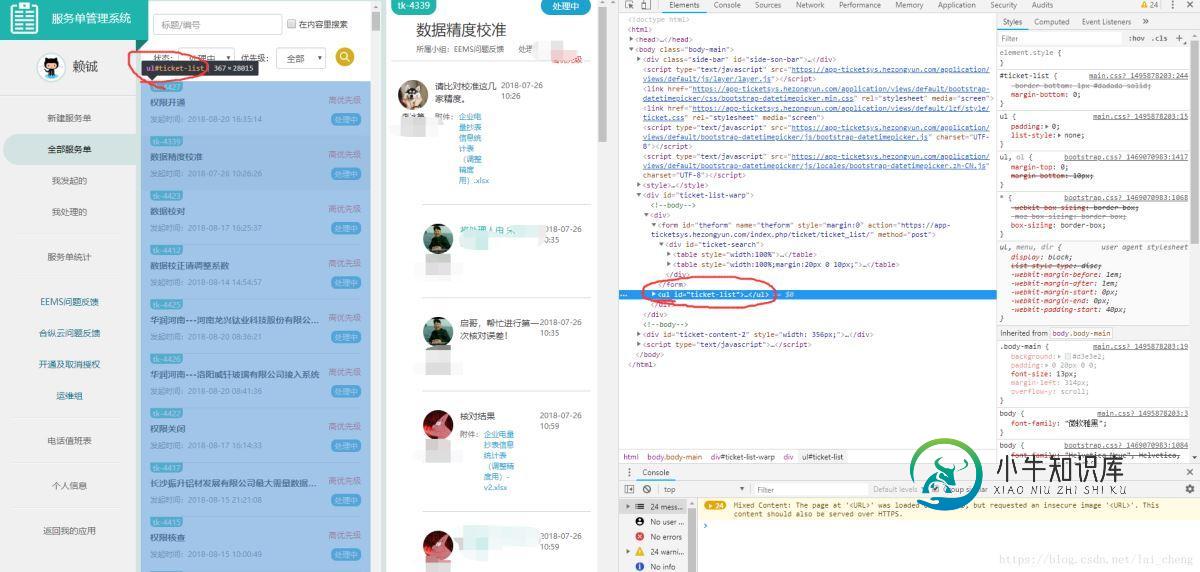
按箭头点击到对应工单大块,可以查询到,所有的工单号,工单发起时间,工单标题均在<ul id =“ticket-list”>这个id下面

那么点开一个工单结构,例如工单号ID = “4427” 下面我们需要知道工单号,工单发起时间,工单内容可以看到
1.工单内容在H3标签下面
2.工单编号在类=“NUM”下面
3.工单发起时间在类= “时间” 下面
for soups in soup.select('#ticket-list'):
if len(soups.select('h3'))>0:
id_num = soups.select('.num')
star_time = soups.select('.time')
h3 = soups.select('h3')
print id_num,start_time,h3
总结
以上所述是小编给大家介绍的python抓取需要扫微信登陆页面,希望对大家有所帮助,如果大家有任何疑问请给我留言,小编会及时回复大家的。在此也非常感谢大家对小牛知识库网站的支持!
如果你觉得本文对你有帮助,欢迎转载,烦请注明出处,谢谢!
-
本文向大家介绍Python版实现微信公众号扫码登陆,包括了Python版实现微信公众号扫码登陆的使用技巧和注意事项,需要的朋友参考一下 基于python 实现公众扫码登陆 前提 申请公众号服务,配置相关信息,并在相关平台进行配置,就这么多东西 实现逻辑,使用临时临时二维码,带参数的二维码扫码登陆 流程,用户已经扫码关注,在登陆页面直接扫码登陆, 用户未关注,则需要点击关注后,直接登录, 我们使用带
-
本文向大家介绍php实现微信扫码自动登陆与注册功能,包括了php实现微信扫码自动登陆与注册功能的使用技巧和注意事项,需要的朋友参考一下 本文实例讲述了php实现微信扫码自动登陆与注册功能。分享给大家供大家参考,具体如下: 微信开发已经是现在程序员必须要掌握的一项基本的技术了,其实做过微信开发的都知道微信接口非常的强大做起来也非常的简单,这里我们一起来看一个微信自动登陆注册的例子. php 微信扫码
-
1. 申请应用 登录微信企业版控制台:控制台 (opens new window) 如果没有企业可以点击 “企业注册”注册企业后再登录控制台 创建企业微信应用:导航栏 – 应用管理 – 自建 – 创建应用 设置企业微信授权登录 创建完应用之后,拖到应用最下方,选择“设置企业微信授权登录” 设置“Web网页”应用的“授权回调域” 注意 这里 “授权回调域” 不需要指定 “前缀、后缀” 等信息,示例如
-
问题内容: 首先,我认为值得一提,我知道有很多类似的问题,但是没有一个对我有用。 我是Python,html和网络抓取工具的新手。我正在尝试从需要先登录的网站上抓取用户信息。在我的测试中,我以来自github的scraper我的电子邮件设置为例。主页是“ https://github.com/login ”,目标页面是“ https://github.com/settings/emails ” 这
-
我是python新手,正在尝试从以下站点获取数据。虽然这段代码适用于不同的站点,但我无法让它适用于nextgen stats。有人想知道为什么吗?下面是我的代码和我得到的错误 下面是我得到的错误 df11=pd。读取html(urlwk1)回溯(上次调用):文件“”,第1行,在文件“C:\Users\USERX\AppData\Local\Packages\PythonSoftwareFounda
-
本文向大家介绍微信小程序-详解微信登陆、微信支付、模板消息,包括了微信小程序-详解微信登陆、微信支付、模板消息的使用技巧和注意事项,需要的朋友参考一下 微信公众平台近日悄然开始内测微信小程序(微信公众号)功能,引来无数开发者和普通用户关注,微信支付的能力,是随着小程序的发布一并推出的,具有介绍如下: wx.login(OBJECT) 调用接口获取登录凭证(code)进而换取用户登录态信息,包括用户
-
本文向大家介绍对python抓取需要登录网站数据的方法详解,包括了对python抓取需要登录网站数据的方法详解的使用技巧和注意事项,需要的朋友参考一下 scrapy.FormRequest login.py selenium登录获取cookie get_cookie_by_selenium.py 获取浏览器cookie(以Ubuntu的Firefox为例) get_cookie_by_firefo
-
调起微信扫一扫接口 wx.scanQRCode({ needResult: 0, // 默认为0,扫描结果由微信处理,1则直接返回扫描结果, scanType: ["qrCode","barCode"], // 可以指定扫二维码还是一维码,默认二者都有 success: function (res) { var result = res.resultStr; // 当needR